PostgreSQL Tutorial
The PostgreSQL Development Team
Edited by
Thomas Lockhart
和訳
日本PostgreSQLユーザー会

PostgreSQL Tutorial
Covering v6.5 for general release
by The PostgreSQL Development Team
Edited by Thomas Lockhart
(last updated 1999-05-19)
Translated by Japan PostgreSQL User Group (1999-11-06)
PostgreSQL is Copyright 1996-9 by the Postgres
Global Development Group.
-
-
目 次
-
-
要約
-
1. 紹介
-
Postgresとは?
-
Postgresの簡単な歴史
-
バークレイ Postgres プロジェクト
-
Postgres95
-
PostgreSQL
-
リリースについて
-
リソース
-
用語
-
表記
-
2000年問題
-
Copyrights and Trademarks
-
2. SQL
-
リレーショナルデータモデル
-
リレーショナルデータモデルの形式
-
ドメイン 対 データ型
-
リレーショナルデータモデルでの操作
-
リレーショナル代数
-
リレーショナル計算
-
タプルリレーショナル計算
-
リレーショナル代数 対 リレーショナル計算
-
SQL 言語
-
選択
-
データ定義
-
データの取扱
-
システムカタログ
-
埋め込み SQL
-
3. アーキテクチャ
-
Postgres アーキテクチャの概念
-
4. スタート
-
環境の整備
-
対話型モニタ (psql) のスタート
-
データベースの管理
-
データベースの作成
-
データベースへのアクセス
-
データベースの削除
-
5. 問い合わせ言語
-
対話型モニタ
-
概念
-
新規クラスの作成
-
インスタンスのクラスへの挿入
-
クラスの問い合わせ
-
SELECT 問い合わせのリダイレクト
-
クラスの結合
-
更新
-
削除
-
集計関数の使用
-
6. 高度な Postgres SQL の特徴
-
継承
-
非原子的な値
-
配列
-
タイムトラベル
-
さらに高度な特徴
-
文献
要約
UCバークレイのコンピュータサイエンス科で最初に開発された Postgresは、 現在いくつかの商用データベースでの利用可能になりつつある
オブジェクト-リレーショナル概念の多くを開拓してきました。 SQL92/SQL3 言語のサポート、完全なトランザクション、
そして型の拡張を提供しています。 PostgreSQL はパブリックドメインでオープンソースの、
オリジナルのPostgresバークレイコードの後継となります。
Chapter 1. 紹介
-
目 次
-
Postgresとは
-
Postgresの簡単な歴史
-
リリースについて
-
リソース
-
用語
-
表記
-
2000年問題
-
Copyrights and Trademarks
この文書はカリフォルニア大学バークレイ校にて開発されたデータベース管理システム
PostgreSQL
のユーザマニュアルです。 PostgreSQLは Postgres
release 4.2 に基づいています。 Michael Stonebraker教授の率いる Postgres
プロジェクトは、 Defense Advanced Research Projects Agency (DARPA)、 Army
Research Office (ARO)、 the National Science Foundation (NSF)、 ESL, Inc.
をスポンサーとしていました。
Postgresとは?
伝統的なリレーショナル・データベース管理システム (DBMS)で、 特定の型の属性を含む名前付きリレーションの集合から成る
データモデルをサポートしています。 現在の商用システムでは、 可能な型として、小数、整数、文字列、通貨、日付の型が含まれています。
一般にこのモデルは将来のデータ処理アプリケーションには 不十分であると認識されています。
関係モデルは "スパルタ人の実直さ" から 先のモデルを部分的に置き換えることに成功しています。
しかし、既に触れたように、この実直さがアプリケーションの インプリメントを非常に難しくしてしまうことがよくあります。
Postgres はユーザが容易にシステムを拡張するための 次の 4つの付加的な基本概念を組み込むことで、重要な追加パワーを提供しています:
他にもの追加パワーと柔軟性を提供する特徴があります:
このような特徴が Postgresを オブジェクトリレーショナル とされるデータベースのカテゴリに置いています。
通常、伝統的なリレーショナルデータベース言語をサポートすることに向いていない オブジェクト指向
とされるものとはまったく別物であることに注意してください。 ですから、Postgres
は いくらかのオブジェクト指向の特徴を持ってはいますが、 リレーショナルデータベースの世界にしっかりと存在しています。
実際、いくつかの商用データベースは最近 Postgres が率先してきた特徴を組み込み始めました。
Postgresの簡単な歴史
現在PostgreSQLとして知られている (またしばらくの間Postgres95と呼ばれていた)
オブジェクトリレーショナルデータベース管理システムは バークレーで書かれたパッケージPostgres
から派生しています。
その後10年以上にもわたる開発によって、PostgreSQL
は最も先進的なオープンソースデータベースとなりまし
た。これはどこででも入手可能で、MVCC(multi-version concurrency
control --- 表レベルでの排他制御に代わる、多重バージョンを使用し
た並行クエリー処理制御機構)を提供し、
ほとんどすべての SQL
の概念( サブセレクト、トランザクション、 ユーザ定義の関数と型を含む )をサポートし、
幅広い言語バインド( C、C++、Java、perl、tcl、python を含む )を持ちます。
バークレイ Postgres プロジェクト
Postgres DBMS の実装は 1986年に始まりました。 システムの最初の構想はThe
Design of Postgresに紹介され、 最初のデータモデルの定義は The
Postgres Data Model に 現れました。 当時のルールシステムの設計は
The
Design of the Postgres Rules System に説明されていました。 The
Postgres Storage System. 記憶領域管理の構造理論は The
Postgres Storage System に詳しく説明されていました。
それから Postgres はいくつかのメジャーリリースを経験してきました。 最初の
"デモウェア" システムが 1987 年に使えるようになり、 1888 年の ACM-SIGMOD
会議でお目見えしました。 The
Implementation of Postgres に説明されるバージョン 1 を、 1989 年
1 月に数人の外部ユーザへリリースしました。 最初のルールシステム (A
Commentary on the Postgres Rules System) の批評に応えて、 ルールシステムは再設計され
(On
Rules, Procedures, Caching and Views in Database Systems)、 新しいルールシステムとともにバージョン
2 が 1990 年 6 月にリリースされました。 複数保存領域管理、問い合わせ実行モジュールの改善、
書き直した書き換えルールシステムのサポートが追加された バージョン 3 が
1991 年に出されました。 それから Postgres95 (下記参照) までのリリースは、
大方、移植性と信頼性の向上に焦点が合わされていました。
Postgres は色々な研究や製造のアプリケーションを実装するのに使われてきました。
これらには 財務データ分析システム、 ジェットエンジンのパフォーマンスモニター・パッケージ、
惑星軌道追跡データベース、 その他、地理情報システムなどが含まれています。
Postgresはまた いくつかの大学で教育ツールとしても使われてきました。 最終的には、Illustra
Information Technologies (その後 Informix
に合併されました) がコードを取り出し、商品化しました。 Postgres は 1992
年後半の科学計算プロジェクト Sequoia
2000 の基本データマネージャとなりました。
1993 年中に外部ユーザコミュニティのサイズは倍近くになりました。 プロトタイプのコードのメンテナンスとサポートは、
データベースの研究に当てるべき時間の多くを取っていくことは ますます明白となりました。
このサポート負担を軽減しようとする中で、 プロジェクトは公的には バージョン
4.2 で終りを告げました。
Postgres95
1994 年、 Andrew Yu と Jolly
Chen が SQL 言語のインタプリタを Postgres に加えました。 続く Postgres95
は パブリックドメイン、オープンソースで、 オリジナルのPostgresバークレイコードの後継として、
独自の世界を見つけ出そうと、Web でリリースされました。
Postgres95 コードは完全に ANSI C であり、 そのサイズは 25% 切り落とされました。
多くの内部的な変更で、パフォーマンスとメンテナンス性が向上しました。 Postgres95
v1.0.x は Postgres v4.2 と比べて Winsconsin ベンチマークで 約 30-50% 速く動きました。
バグフィクスは別として、次のような主な機能拡張があります。
問い合わせ言語 Postquel は SQL (サーバに実装されました) に置き換えられました。
副問い合わせは PostgreSQL (下記参照) となるまでは サポートされていませんでしたが、Postgres95
でも ユーザ定義の SQL 関数によって疑似的に可能でした。 集計関数が再実装されました。
GROUP BY 句のサポートも加えられました。 libpq のインターフェイスは
C プログラムのために残っています。
monitor プログラムに加えて、 GNU の readline を使い インタラクティブに
SQL 問い合わせを行なう 新しいプログラム (psql) が提供されました。
新しいフロントエンドライブラリ libpgtcl が Tclベースのクライアントをサポートしました。
サンプルシェルの pgtclsh が tcl と Postgres95 バックエンドとを結ぶ 新しい
Tcl コマンドと提供しました。
巨大オブジェクトのインターフェイスがオーバーホールされました。
転置巨大オブジェクト(Inversion large object)は巨大オブジェクトを格納する
唯一のメカニズムでした。(転置(Inversion)ファイルシステムは削除されました。)
インスタンスレベルでのルールシステムが削除されました。 今は、書き換えルールとして利用できます。
正規の SQL の特徴を紹介する短いチュートリアルが、 Postgres95 のものと共にソースコードと一緒に配布されました。
GNU make が(BSD makeの代わりに) ビルドに使われました。 また、Postgres95
はパッチを当てていない gcc で コンパイルできました(double のデータ並びが修正されました)。
PostgreSQL
1996 年には、“Postgres95”という名前の持つ年号が当然そぐわなくなりました。
オリジナルのPostgres と、SQL の能力を持つ最新のバージョンとの関係を反映する、
PostgreSQLという新しい名前を選びました。 同時に、元々Postgresプロジェクトで始まった
順番を踏襲する番号の 6.0 で始まるバージョン番号をつけました。
Postgres95の開発での重点は バックエンドのコード中にある既存の問題点を見極めることにありました。
PostgreSQL の開発作業は、すべての領域で続けてますが、 重点は機能や性能を向上させることにシフトしました。
主な PostgreSQL での機能拡張には以下のものがあります。
表レベルでのロッキングが MVCC (multi-version concurrency control)
で 置き換えられました。 これは、書き込み側がアクティビティの間も読み出し側は一貫性のあるデータを
読み続けることができて、 データベースが問い合わせ可能な状態にの間も pg_dump
によってホットバックアップを可能にするものです。
副問い合わせ、デフォルト値、制約、トリガといった重要なバックエンドの特徴が
実装されました。
プライマリキー、クオートされた記述子、強制型指定、型キャスト、 バイナリと16進整数入力を含む、追加的な
SQL92 準拠の 言語の特徴が加えられました。
組み込み型が改善されて、新たに日付/時間型の幅広い指定、追加的な幾何学型のサポート
が含まれます。
v6.0 がリリースされたときから比べて 、バックエンドコード全体のスピードがおおよそ 20-40% 向上し、 バックエンドの起動時間は 80% 減少しました。
リリースについて
PostgreSQL の利用にコストはかかりません。このマニュアルは PostgreSQL のバージョン6.5について述べています。
ここからは、 Postgres が PostgreSQL として配布されているバージョンのことを意味することにします。
現在サポートされているマシンのリストについては管理者ガイドをチェックして下さい。
一般的には、完全な libc ライブラリをサポートしている Unix/Posix
互換であれば、どんなシステムでも Postgres を移植できます。
リソース
マニュアルセットはいくつかのパートで構成されています。
-
チュートリアル
知らない人のためのイントロダクションです。 先進的な機能はカバーしていません。
-
ユーザガイド
ユーザのための一般的な情報で、利用可能なコマンドやデータ型が含まれています。
-
プログラマガイド
アプリケーションプログラマのための一歩進んだ情報です。 トピックとしては、型や関数の拡張、ライブラリのインタフェイスや
アプリケーションの設計などについてを論点としています。
-
管理者ガイド
インストールと管理の情報。サポートされているマシンのリスト。
-
開発者ガイド
Postgres 開発者のための情報です。 Postgres プロジェクトに貢献しようとしている人を
対象としています。 アプリケーション開発のための情報はプログラマガイドにあります。
現在のところ、プログラマガイドに含まれています。
-
リファレンスマニュアル
コマンドの文法についての詳細です。 現在 ユーザガイドに含まれています。
このマニュアルセットに加えて、Postgres のインストールや使い方についての助けとなるリソースがあります。
-
man ページ
man ページにはコマンドの文法についての一般的な情報があります。
-
FAQ
よく訊かれる質問 (FAQ) の文書に一般的なことから プラットフォームに依存したことまでの論点が置かれています。
-
README
いくつかの貢献されたパッケージについての README ファイルが利用できます。
-
Web サイト
Postgres の Web サイトには、配布パッケージにはない情報があります。
メーリングリストのトラフィックのmhonarcカタログがあり、 多くのトピックについての豊富なリソースとなります。
-
メーリングリスト
pgsql-general
(アーカイブ)
メーリングリストはユーザの質問に答えてくれるよい場所です。 他のメーリングリストもあります。
詳細は PostgreSQL WEB サイトの Info Central セクションを参考にしてみてください。
-
あなた自身!
Postgresはオープンソースの成果です。 ですから、ユーザコミュニティにサポートを依存しています。
Postgres を使い始めると、 ドキュメントやメーリングリストを通じて誰かの助けに頼るでしょう。
あなたの得た知識をフィードバックすることも考えてください。 ドキュメントにないことを学んだら、それを書き物にして貢献してください。
なにか特色をコードに加えたら、それを貢献してください。
充分な経験がないような人でもドキュメントの修正や小さな変更は提供できます。
それが始めるにあたって良い方法でしょう。 pgsql-docs
(アーカイブ)
メーリングリストで行なわれています。
次のドキュメントでは サイトは Postgres がインストールされた ホストマシンとして解釈されます。
単一のホスト上にひとつ以上のPostgres データベース群をインストールすることができますので、
この用語は、もっと正確には、 インストールされたPostgres のバイナリとデータベース
の特定の集合を意味します。
Postgres の スーパユーザ は postgres という名前のユーザで、
Postgres バイナリとデータベースのファイル を所有する者です。 データベースのスーパユーザとして、
すべての保護メカニズムは無視され、すべてのデータに任意にアクセスできます。
加えて、Postgres のスーパユーザは 通常すべてのユーザは利用できないいくつかのサポートプログラムを
実行することが許されています。 Postgres のスーパユーザは、 (rootとして参照できる)Unix
のスーパユーザと 同じではないことに注意してください。 スーパユーザはゼロ以外のユーザID
(UID) を持っています。
データベース管理者 もしくは DBA はサイトのセキュリティ方針を強要するメカニズムで
Postgres をインストールする責任を持つ人です。 DBA は下記の方法で新しいユーザを加えることができ、
createdb で使われる テンプレートデータベースのセットを維持します。
postmaster は Postgres システムへのリクエストのための 交換所の役割を果たすプロセスです。
フロントエンドアプリケーションは システムエラーやバックエンドプロセスとの接続を追跡する
postmaster に接続します。 postmaster はその動作を調整するために、 いくつかのコマンドライン引数を取ることができます。
しかしながら、引数を与えることは、 複数のサイトやデフォルトとは違うサイトを走らせようとする時
のみに必要となるものです。
Postgres バックエンド (実際の実行プログラム postgres)は、 Postgres
スーパユーザが (データベース名を引数として) ユーザシェルから直接実行することができます。
しかしながら、こうすることは postmaster/サイトに関連付けられた共有バッファプールやロックテーブル
を無視するので、マルチユーザのサイトではお勧めできません。
表記
ファイル名の頭の “...” や /usr/local/pgsql/ は Postgres のスーパユーザの
ホームディレクトリへのパスを表現するのに使われています。
コマンドの書式での角括弧 (“[” と “]”) は、オプションのフレーズやキーワードを示しています。
大括弧(“{” と “}”)の中にあって、 縦棒 (“|”) を含んでいるものは、
どれかひとつを選ばなくてはいけないことを示しています。
例では、丸括弧 (“(” と “)”) を ブール表現のグループ化に使っています。
“|” はブール型演算子 OR です。
例では色々なアカウントやプログラムから実行されたコマンドを表示しています。
root アカウントから実行されたコマンドは、 前に“>” がつきます。 Postgres
のスーパーユーザのアカウントから 実行されたコマンドは、前に “%” がつき、
権限のないユーザのアカウントから実行されたコマンドは “$” が前につきます。
SQL コマンドには、状況によって、“=>” がつく場合もあるし、プロンプトが無い
場合もあります。
NOTE: 執筆時点(Postgres v6.5)で、 ドキュメントセットを通じて、
印を付けるコマンド群にたしての記述には一貫性があるわけではありません。
問題点は ドキュメンテーションメーリングリスト
へレポートしてください。
2000年問題
Author: Written by Thomas
Lockhart on 1998-10-22.
The PostgreSQL Global Development Team は Postgres ソフトウェアの
コードツリーを、無保証で動作やパフォーマンスに関しては責任を持たないパ
ブリックサービスとして提供しています。しかし、執筆時点においては:
1996年11月から Postgres サポートチームのボランティアであるこのス
テートメントの筆者は、Postgres のコードベースで 2000年の1月1日 (Y2K)
での時間の移行での問題に関して何も気になるところはありません。
このステートメントの筆者は regression テストでカバーされていない、
あるいは、最近から現在にかけて Postgres のバージョンで使われているその
他の分野においても、2000 年問題 に関するいかなる報告も受けておりません。
もし、問題が存在するなら、インストールされた基やサポートメーリングリス
ト上のユーザの活発な参加で、その問題について知らされることを期待してい
ました。
筆者の認識の限りでは、2桁の年で指定される日付についての Postgres
の実装は、現在のユーザガイ
ドのデータ型の章で文書化されています。2桁の年について、重要な
別れ目の年は 2000 年ではなく、1970 年です。例えば、“70-01-01” は
“1970-01-01” と解釈されますが、“69-01-01” は “2069-01-01” と解釈
されます。
OSに潜む「現在時間」の取得に関する 2000年問題は、
Postgres の 2000年問題へも明らかに伝搬します。
特にオープンソース、無料ソフトウェアについての2000年問題に関
するこれ以上の論点につきましては、
The
Gnu ProjectとThe Perl
Instituteを参照してください。
Copyrights and Trademarks
PostgreSQL is Copyright 1996-9 by the PostgreSQL Global Development Group,
and is distributed under the terms of the Berkeley license.
Postgres95 is Copyright 1994-5 by the Regents of the University of California.
Permission to use, copy, modify, and distribute this software and its documentation
for any purpose, without fee, and without a written agreement is hereby
granted, provided that the above copyright notice and this paragraph and
the following two paragraphs appear in all copies.
In no event shall the University of California be liable to any party
for direct, indirect, special, incidental, or consequential damages, including
lost profits, arising out of the use of this software and its documentation,
even if the University of California has been advised of the possibility
of such damage.
The University of California specifically disclaims any warranties,
including, but not limited to, the implied warranties of merchantability
and fitness for a particular purpose. The software provided hereunder is
on an "as-is" basis, and the University of California has no obligations
to provide maintainance, support, updates, enhancements, or modifications.
UNIX is a trademark of X/Open, Ltd. Sun4, SPARC, SunOS and Solaris are
trademarks of Sun Microsystems, Inc. DEC, DECstation, Alpha AXP and ULTRIX
are trademarks of Digital Equipment Corp. PA-RISC and HP-UX are trademarks
of Hewlett-Packard Co. OSF/1 is a trademark of the Open Software Foundation.
Chapter 2. SQL
-
目 次
-
リレーショナルデータモデル
-
リレーショナルデータモデルの形式
-
リレーショナルデータモデルでの操作
-
SQL 言語
この章は、もとは Stefan Simkovics' Master's
Thesis (Simkovics, 1998) の一部として出たものです。
SQL は最も人気のあるリレーショナル問い合わせ言語となりました。 “SQL”という名前は
Structured
Query Language の省略です。 1974 年、Donald Chamberlin などが、IBM
リサーチで SEQUEL 言語 (Structured English Query Language) を定義しました。
この言語は最初 SEQUEL-XRM と呼ばれる IBM のプロトタイプに 1974-75年に実装されました。
1976-77年には、SEQUEL/2 と呼ばれる SQUEL の改訂版が定義され、 その名前がその後
SQL と変更されました。
システムR と呼ばれる新しいプロトタイプが IBM で 1977 年に開発されました。
システム R は SEQUEL/2 (現在の SQL) の大きなサブセットを実装し、 このプロジェクトで多くの変更が
SQL になされました。 システム R は IBM 内部のサイトと、またいくつかの選択されたカスタマーサイトのとの両方の、
多くのユーザサイトにインストールされました。 そのようなユーザサイトへ首尾よく受け入れられたおかげで、
システム R のテクノロジーをベースとして SQL言語を実装した商用製品を IBM
は開発し始めました。
その後数年の間に IBM や多くのその他のベンダーが SQL製品 をアナウンスしました。それには
SQL/DS (IBM)、 DB2 (IBM)、 ORACLE (Oracle Corp.)、 DG/SQL (Data General
Corp.)、 SYBASE (Sybase Inc.) のようなものがありました。
SQL は現在公式なスタンダードにもなっています。 1982 年には、アメリカ規格協会
(American National Standards Institute, ANSI) がリレーショナル言語の標準への提案を展開させるように、
データベース委員会 X3H2 を設立しました。 この提案は 1986 年に批准され、本質的には
SQL の IBM 方言から成っています。 1987 年にはこの ANSI 標準は、 国際標準化機構(International
Organization for Standardization, ISO)によって 国際標準としても容認されました。
SQL のこのオリジナル標準バージョンは、 しばしば非公式に "SQL/86" と呼ばれています。
1989 年にはオリジナルの標準は拡張されました。 そしてこの新しい標準はしばしば、これもまた非公式ですが、
"SQL/89" と呼ばれています。 同じく 1989 年に、Database Language Embedded
SQL (ESQL)と呼ばれる関連した標準が開発されました。
ISO と ANSI の委員会は、 非公式にSQL2 やSQL/92として呼ばれる、
オリジナルの標準バージョンを大いに拡張したバージョンの定義に、 何年もの作業を続けています。
このバージョンは 1992 年の後半に採用された標準 - "International Standard
ISO/IEC 9075:1992, Database Language SQL" - となりました。 SQL/92 は、
普通 "標準 SQL" と言う時に意味するバージョンです。 SQL/92 の詳細は Date
and Darwen, 1997 にあります。 このドキュメントを書いている時点で、
SQL3
として呼ばれる 新しい標準が開発途中であります。 SQL を Turing-complete
言語、 すなわちすべての計算可能問い合わせ (例えば再帰的問い合わせ)を可能となるように、
計画されています。 これは非常に複雑なタスクで、これによってその新しい標準の完成は
1999 年以前には期待できません。
リレーショナルデータモデル
上で触れたように、SQL はリレーショナル言語です。 それは、1970年 E.F. Codd
によって最初に出版された リレーショナルデータモデルに基づいている、
ということです。 リレーショナルモデルの正式な記述は後で述べるとして (リレーショナルデータモデルの形式になります)、
直観的な観点からこれを見て行きたいと思います。
リレーショナルデータベース は、 ユーザから 表の集まり
(そして表以外何もない) として 理解されるデータベースです。 表は行と列から成っており、各行はひとつのレコードを表し、
各列は表に含まれるレコードの属性を表すものです。 店と部品データベースでは
3つの表から成るデータベースの例を示しています。
SUPPLIER は店の数(SNO)と名前(SNAME)と街(CITY)を保存する表です。
PART は部品の数(PNO)と名前(PNAME)と価格(PRICE)を保存する表です。
SELLS はどの店(SNO)がどの部品(PNO)を販売したかの情報を保存します。 ある意味でそれは他の2つの表を結びつける役目をしています。
Example 2-1. 店と部品データベース
SUPPLIER SNO | SNAME | CITY SELLS SNO | PNO
-----+---------+-------- -----+-----
1 | Smith | London 1 | 1
2 | Jones | Paris 1 | 2
3 | Adams | Vienna 2 | 4
4 | Blake | Rome 3 | 1
3 | 3
4 | 2
PART PNO | PNAME | PRICE 4 | 3
-----+---------+--------- 4 | 4
1 | Screw | 10
2 | Nut | 8
3 | Bolt | 15
4 | Cam | 25
PART と SUPPLIER の表は 実体 とみなし、 SELLS はある部品とある店との間のリレーションと
考えることができます。
表に対するSQLの操作は既に定義したのと同様ですが、
その定義には後で触れることとして、そのまえに、リレーショナルモデル
のについて考察してみましょう。
リレーショナルデータモデルの形式
リレーショナルモデルの元にある数学的な概念は、 集合論的 リレーションで、
ドメインのリストの直積の部分集合となります。 この集合論的リレーションがこのモデルに名前を付けました
(実体関係(Entity-Relationship)モデルの関係と 混乱しないでください)。
形式的にドメインは単純に値の集合です。 例えば整数の集合はドメインです。
また、20文字の文字列と実数の集合はドメインの例です。
ドメインの直積 D1, D2,
... Dk, を D1 D2
... Dk と表すと、 これはすべての k タプルの集合
v1,
v2,
... vk, ここで
v1
∈ D1,
v1 ∈ D1,
... vk ∈
Dk.
例えば、以下の場合 k=2, D1={0,1}
and D2={a,b,c} then D1D2
is {(0,a),(0,b),(0,c),(1,a),(1,b),(1,c)}.
ひとつのリレーションは1あるいは複数のドメインの直積からなる部分集合です。
R
⊆ D1 D2 ... Dk.
例えば {(0,a),(0,b),(1,a)}というのがひとつのリレーションです。
これは上で触れたように、実際は以下の物の部分集合となります。 D1D2
このリレーションの項をタプルと呼ばれます。ある直積の各関係は D1D2
... Dk k個の成分数を持つといい、 したがってk-タプルの集合となります。
リレーションは表に表されます。(すでにやっています。 店と部品データベースを思い出してください。)
すべてのタプルが行で表され、 すべての列はひとつのタプルの1要素に対応します。
(属性と呼ばれる)名前をカラムに与えることで、 リレーションスキームの定義となります。
リレーションスキーム R は、属性 A1,
A2,
... Ak の有限集合となります。 各属性Aiについて
Diというドメインがあり、
1 <= i <= k です。 そこから属性の値は取り出されます。
しばしばリレーションスキームを
R(A1, A2,
... Ak) と書きます。
NOTE: リレーションスキーム は一種のテンプレートですが、
リレーション
は リレーションスキーム のひとつのインスタンスとなります。 リレーションはタプルで構成されます(そしてそれによって
表として見ることができます)。 リレーションスキームはそうではありません。
ドメイン 対 データ型
この前のセクションでは、しばしば ドメイン について述べました。 ドメインは、形式的に、単なる値の集合(例えば整数や実数の集合)であることを
思い出してください。 データベースシステムに関して、 ドメインの代わりにデータ型
についてお話します。 表を定義する時、どの属性を含めるかを決定しなくてはなりません。
さらに、どのような種類のデータが属性値として保存さようとしているのか を決めなくてはなりません。
例えば、表 SUPPLIER の SNAME の 値は文字列ですが、SNO は整数を保存します。
各属性にデータ型を割り当てることによってこれを定義するのです。 SNAME の型は
VARCHAR(20) (これは、長さ <= 20 の文字列のための SQLの型です) となり、SNO
の型はINTEGER となります。 データ型を割り当てることで、 属性のドメインをも選択したことになります。
SNAME のドメインは 長さ <= 20 のすべての文字列の集合となり、 SNO のドメインは、
すべての整数の集合となります。
リレーショナルデータモデルでの操作
前のセクション(リレーショナルデータモデルの形式)では、
リレーショナルモデルの数学的考えを定義しました。 今データがリレーショナルモデルを用いてどのように保存されるかは知りましたが、
まだデータベースから何かを取り出すために、 これらすべてのテーブルで何をすればよいかを知りません。
例えば、誰かが部品の 'ネジ' を売るすべての店の名前を訊いたとしましょう。
これによって、リレーション上での操作を表現するために、 2つの幾分か異なる種類の表記法が定義されました。
リレーショナル代数
リレーショナル代数 は 1972 年 E. F. Codd によって紹介されました。
リレーション上での操作の集合から成っています。
選択(SELECT) (σ): 与えられた制約を満たすタプルを リレーションから引き出します。
R
は属性 A を含む表にしてください。 σA=a(R) =
{t ∈ R ? t(A) = a} ここで t は R のタプルを示し、
t(A)
はタプルtの 属性Aの値を示します。
射影(PROJECT) (π): 指定した属性 (カラム) を リレーションから引き出します。
R は属性Xを含む リレーションにしてください。 πX(R) = {t(X)
? t ∈ R}, t(X) は タプルtの 属性Xの値を示します。
直積(PRODUCT) (×): 2つのリレーションの直積を作ります。 R は要素数 k1
の表で、 S は要素数 k2 としてください。 R × S はすべての
k1
+ k2-タプルの集合で、 R のタプルから最初の
k1
要素と、 S のタプルの最後の k2 要素です。
結合(UNION) (∪): 2つの表の集合論的和をとります。 表R と S (両方とも同じ次数でなくてはなりません)を与えられた
和 R ∪ S は R か S、もしくは両方に 属するタプルの集合です。
積(INTERSECT) (∩): 2つの表の集合論的積を作ります。 表R と S を与えられた
R ∪ S は R と S に属するタプルの集合です。 これもまた R と S が 同じ次数でなくてはなりません。
差(DIFFERENCE) (− もしくは ?): 2つの表の差集合を作ります。 R と S は、
これもまたおなじ次元の2つの表となります。 R - S は R に属しますが、Sには属さない
タプルの集合となります。
結合(JOIN) (Π): 2つの表をその共通属性で結合します。 R は属性A,B, C
を持つ表にします。 また S は属性C,D E を持つ表にします。 両方のリレーションに共通な属性は、属性
C だけとなります。 R Π S = πR.A,R.B,R.C,S.D,S.E(σR.C=S.C(R
× S))。 ここでは何をしているのでしょうか? まず最初に直積 R S を計算します。
そして共通する属性 C が等しい値となる (σR.C = S.C) タプルを選択します。
ここでは属性 C を2度含む表があり、 重複したカラムを射影することで修正します。
Example 2-2. 内結合
結合に必要なステップを評価することから生じた表を見てみることにしましょう。
次の2つの表が与えられているとします。
R A | B | C S C | D | E
---+---+--- ---+---+---
1 | 2 | 3 3 | a | b
4 | 5 | 6 6 | c | d
7 | 8 | 9
まず直積 R × S を 計算して、次のものを得ます。
R × S A | B | R.C | S.C | D | E
---+---+-----+-----+---+---
1 | 2 | 3 | 3 | a | b
1 | 2 | 3 | 6 | c | d
4 | 5 | 6 | 3 | a | b
4 | 5 | 6 | 6 | c | d
7 | 8 | 9 | 3 | a | b
7 | 8 | 9 | 6 | c | d
σR.C=S.C(R × S) の選択によって、次のものが得られます。
A | B | R.C | S.C | D | E
---+---+-----+-----+---+---
1 | 2 | 3 | 3 | a | b
4 | 5 | 6 | 6 | c | d
重複したカラム S.C を削除するために、次の操作で射影を取ります。
πR.A,R.B,R.C,S.D,S.E(σR.C=S.C(R × S)) そして次のものが得られます。
A | B | C | D | E
---+---+---+---+---
1 | 2 | 3 | a | b
4 | 5 | 6 | c | d
商(DIVIDE) (÷): R は 属性 A,B,C,D を持つ表とします。そして S が属性 C,D
を持つ表だとします。 そこで差を次のように定義します。 R ÷ S = {t ? ∀
ts ∈ S ∃ tr ∈ R これは、 tr(A,B)=t∧tr(C,D)=ts}
ここで tr(x,y) は 要素x と y のみから成る
表Rのタプルを示します。 タプル t は、リレーションR の要素A と
B のみから 成ることに注意してください。
次のような表が与えられて、
R A | B | C | D S C | D
---+---+---+--- ---+---
a | b | c | d c | d
a | b | e | f e | f
b | c | e | f
e | d | c | d
e | d | e | f
a | b | d | e
R ÷ S で次のものを得ます。
A | B
---+---
a | b
e | d
リレーショナル代数のもっと詳しい記述や定義については、 [Ullman,
1988] または [Date, 1994] を参照してください。
Example 2-3. リレーショナル代数を使った問い合わせ
データベースからデータを取り出すことができるように、 すべてのリレーショナル演算子は式にすることを思い出して下さい。
前のセクション(リレーショナルデータモデルでの操作)
からの例に戻ってみましょう。 ここでは、だれかが部品ネジを売っている
すべての店の名前を知りたいとしていました。 この問いには、リレーショナル代数を使い、次の操作で答えることができます。
πSUPPLIER.SNAME(σPART.PNAME='Screw'(SUPPLIER Π SELLS Π PART))
このような操作を問い合わせと呼びます。 もし例の表(
店と部品データベース)
に対する上記問い合わせを評価するなら、 次のような結果を得ることになるでしょう。
SNAME
-------
Smith
Adams
リレーショナル計算
リレーショナル計算は一階述語論理 に基づいています。 リレーショナル計算には2つの異形があります。
タプルリレーショナル計算だけを論じようと思います。 というのも、それが多くのリレーショナル言語の基礎となるものだからです。
DRC (とTRCについても) についての詳細は、 [Date, 1994]
もしくは [Ullman, 1988] を参照してください。
タプルリレーショナル計算
TRC で使われる問い合わせは次のような形式になります。 x(A) ? F(x) ここで
x
はタプル変数で、 Aは属性の集合、 そして F は式です。 結果のリレーションは
F(t)
を満たす すべてのタプル t(A) となります。
例 リレーショナル代数を使った問い合わせ
の問い合わせに TRC を使って答えるなら、 次のような問い合わせを組み立てます。
{x(SNAME) ? x ∈ SUPPLIER ∧ \nonumber
∃y ∈ SELLS ∃z ∈ PART (y(SNO)=x(SNO) ∧ \nonumber
z(PNO)=y(PNO) ∧ \nonumber
z(PNAME)='Screw')} \nonumber
店と部品データベース からの表に対する問い合わせを評価すると、
これもまた リレーショナル代数を使った問い合わせ
と同じ結果となります。
リレーショナル代数 対 リレーショナル計算
リレーショナル代数とリレーショナル計算は同じ 表現能力を持っています。
つまり、 リレーショナル代数で組み立てることのできるすべての問い合わせは、
反対にリレーショナル計算を使っても組み立てることができます。 これは 1972年に
E. F. Codd によって最初に証明されました。 この証明はあるアルゴリズム(“Codd's
reduction algorithm”) に基づいています。これによって、任意のリレーショナル計算の式は、
リレーショナル代数の表現と意味的に同じに変えることができるのです。 これについての詳細については、
[Date, 1994] と [Ullman,
1988] を参照してください。
リレーショナル計算に基づく言語は、 リレーショナル代数に基づく言語よりも、
"ハイレベル" もしくは "宣言的(more declarative)" と言われることがあります。
これは、代数が (部分的に) 操作の順番を指定するのに対して、 計算ではコンパイラやインタープリタが
もっと効率的な評価の順序を決めるように残しているからです。
SQL 言語
現在のリレーショナル言語ではよくあるが、 SQL はタプルリレーショナル計算に基づいています。
その結果、タプルリレーショナル計算 (もしくは同様に、リレーショナル 代数)
を使って組み立てることのできるすべて問い合わせは、 SQL を用いて組み立てることもできます。
しかしながら、リレーショナル代数や計算の範疇を超えた能力があります。 ここにリレーショナル代数や計算の要素ではない、
SQLが提供するのいくつかの付加的な特徴を挙げてみます。
データの挿入や削除や更新のためのコマンド
算術能力: SQL では、 比較と同様に、算術演算を伴うことができます。例えば、
A < B + 3. + やその他の算術演算子はリレーショナル代数やリレーショナル計算には
現われないことに注意してください。
割当と出力のコマンド: 問い合わせによって作成されたリレーションを出力したり、
あるリレーション名に計算されたリレーションを割り当てることができます。
集計関数: average, sum, max などといった操作を、ひとつの数量として得るために
リレーションのカラムとして適用することができます。
選択
SQL でもっともよく使われるコマンドは SELECT 文で、 データを検索するために使われます。
文法は次のようになります。
SELECT [ALL|DISTINCT]
{ * | expr_1 [AS c_alias_1] [, ...
[, expr_k [AS c_alias_k]]]}
FROM table_name_1 [t_alias_1]
[, ... [, table_name_n [t_alias_n]]]
[WHERE condition]
[GROUP BY name_of_attr_i
[,... [, name_of_attr_j]] [HAVING condition]]
[{UNION [ALL] | INTERSECT | EXCEPT} SELECT ...]
[ORDER BY name_of_attr_i [ASC|DESC]
[, ... [, name_of_attr_j [ASC|DESC]]]];
ここでSELECT 文の複雑な文法をいくつかの例をつけて説明します。 例で使われる表は
店と部品データベース
で定義されます。
単純な選択
SELECT 文を使ったいくつかの簡単な例があります。
Example 2-4. 制約付きの単純な問い合わせ
表 PART から、属性 PRICE が 10 より大きいすべてのタプルを取り出すには、
次のような問い合わせを組み立てます。
SELECT * FROM PART
WHERE PRICE > 10;
and get the table:
PNO | PNAME | PRICE
-----+---------+--------
3 | Bolt | 15
4 | Cam | 25
SELECT 文で "*" を使うことで、表からすべての属性を集めます。 もし表 PART
から、属性 PNAME と PRICE だけを取り出したいなら、 次の記述を使います。
SELECT PNAME, PRICE
FROM PART
WHERE PRICE > 10;
このケースでは、結果は次のようになります。
PNAME | PRICE
--------+--------
Bolt | 15
Cam | 25
SQL の SELECT はリレーショナル代数の "射影" に 相当するもので、"選択" ではありません。
(詳細は
リレーショナル代数を参照してください。)
WHERE 句にある制約は、キーワード OR,AND,NOT を使うことで、 論理的に結合することができます。
SELECT PNAME, PRICE
FROM PART
WHERE PNAME = 'Bolt' AND
(PRICE = 0 OR PRICE < 15);
は次のような結果を導出します。
PNAME | PRICE
--------+--------
Bolt | 15
算術演算をターゲットリストや WHERE 句に使うことができます。 例えば、もし2つの部品を手にいれるにはいくらかかるかを知りたいなら、
次のような問い合わせを使えます。
SELECT PNAME, PRICE * 2 AS DOUBLE
FROM PART
WHERE PRICE * 2 < 50;
そして次の結果を得ます。
PNAME | DOUBLE
--------+---------
Screw | 20
Nut | 16
Bolt | 30
キーワード AS の後の DOUBLE という語は、 2番目のカラムの新しいタイトルとなることに注意してください。
このテクニックは、ターゲットリストのすべての要素に使うことができ、 新しいタイトルを結果のカラムに割り当てることができます。
この新しいタイトルはしばしばエイリアス(alias)と呼ばれます。 エイリアスは問い合わせの残りで使うことはできません。
結合
次の例では、結合 がどのように SQL で実現されるかを示しています。
3つの表 SUPPLIER,PART,SELLS をそれらの共通の属性にわたって結合するには、
次の記述を組み立てます。
SELECT S.SNAME, P.PNAME
FROM SUPPLIER S, PART P, SELLS SE
WHERE S.SNO = SE.SNO AND
P.PNO = SE.PNO;
そして次の表を結果として得ます。
SNAME | PNAME
-------+-------
Smith | Screw
Smith | Nut
Jones | Cam
Adams | Screw
Adams | Bolt
Blake | Nut
Blake | Bolt
Blake | Cam
FROM 句で、すべてのリレーションに対してエイリアス名を出しました。 というのは、リレーション間で共通の名前の属性
(SNO と PNO) があったからです。 これで共通の名前の属性を、 単にエイリアス名をつけた属性名にドットをつけたものを頭につけて、
区別することができます。 結合は 内結合
で示されるのと同じ方法で計算されます。 最初は直積 SUPPLIER PART SELLS が得られます。
ここで WHERE 句で与えられた条件を満たすタプルのみが選択されます (すなわち、共通の名前がついた属性は等しくなくてはいけません)。
最後に S.SNAME と P.PNAME 以外のすべてのカラムを吐き出します。
集計操作
SQL は属性の名前を引数に取る集計演算子 (例えば AVG,COUNT,SUM, MIN, MAX)
を提供します。 集計演算子の値は表全体の指定された 属性(カラム)の値すべてを通じて計算されます。
もし問い合わせでグループが指定されれば、 計算はグループの値を通じてのみ行なわれます
(次のセクションを参照して下さい)。
Example 2-5. 集計
もし表 PART のすべての部品のコストの平均を知りたければ、 次の問い合わせを使います。
SELECT AVG(PRICE) AS AVG_PRICE
FROM PART;
結果は次の通りです。
AVG_PRICE
-----------
14.5
もし表 PART にどれだけの部品があるかを知りたければ、 次の記述を使います。
SELECT COUNT(PNO)
FROM PART;
そして次の値を得ます。
COUNT
-------
4
グループの集計
SQL は表のタプルを分割することを許しています。 それで上記の集計演算子はグループに適用することができます
(つまり、集計演算子の値は指定されたカラムのすべての値に渡ってではなく、
グループのすべての値に渡って計算されます。このように、集計演算子は すべてのグループについてそれぞれ評価されるのです。)
タプルをグループに分割することは、 キーワード GROUP BY に続けて
グループを定義する属性のリストを使うことで行なわれます。 もし GROUP
BY A1, ?, Ak というものがあれば、 2つのタプルが同じグループにあるといったように、
すべての属性 A1, ?, Ak に一致すれば、リレーションをグループに分割します。
Example 2-6. 集計
もし各店がいくつの部品を売ったかを知りたければ、 次のような問い合わせを組み立てます。
SELECT S.SNO, S.SNAME, COUNT(SE.PNO)
FROM SUPPLIER S, SELLS SE
WHERE S.SNO = SE.SNO
GROUP BY S.SNO, S.SNAME;
そして次の結果を得ます。
SNO | SNAME | COUNT
-----+-------+-------
1 | Smith | 2
2 | Jones | 1
3 | Adams | 2
4 | Blake | 3
ここで何が起こっているかを見てみましょう。 まず、表 SUPPLIER と SELLS の結合が得られます。
S.SNO | S.SNAME | SE.PNO
-------+---------+--------
1 | Smith | 1
1 | Smith | 2
2 | Jones | 4
3 | Adams | 1
3 | Adams | 3
4 | Blake | 2
4 | Blake | 3
4 | Blake | 4
次に 属性 S.SNO と S.SNAME の両方に一致するすべてのタプルをまとめて、 タプルをグループに分割します。
S.SNO | S.SNAME | SE.PNO
-------+---------+--------
1 | Smith | 1
| 2
--------------------------
2 | Jones | 4
--------------------------
3 | Adams | 1
| 3
--------------------------
4 | Blake | 2
| 3
| 4
この例では、4つのグループを得ました。そしてここで集計演算子 COUNT を すべてのグループに適用して、上で与えられた問い合わせの全体の結果を導出します。
GROUP BY を使った問い合わせの結果と集計演算子が意味をなすように、 グループ化された属性はターゲットリストに現われなくてはなりません。
すべての GROUP BY 句に現われないそれ以上の属性は 集計関数を使ってのみ選択することができます。
一方、GROUP BY 句に現われる属性に対して、 集計関数を使うことはできません。
Having
HAVING 句は WHERE 句によく似た動作をします。 そして HAVING 句に与えられた制約を満たすグループのみを考えるために使われます。
HAVING 句に許された式は集計関数に関係するものでなくてはなりません。 プレーンな属性のみを使うすべての表現は、WHERE
句に属します。 一方で、集計関数に関する式はすべて HAVING 句に置かなくてはなりません。
Example 2-7. Having
もし1個より多くの部品を売っている店のみが欲しければ、 次の問い合わせを使います。
SELECT S.SNO, S.SNAME, COUNT(SE.PNO)
FROM SUPPLIER S, SELLS SE
WHERE S.SNO = SE.SNO
GROUP BY S.SNO, S.SNAME
HAVING COUNT(SE.PNO) > 1;
そして次のようになります。
SNO | SNAME | COUNT
-----+-------+-------
1 | Smith | 2
3 | Adams | 2
4 | Blake | 3
副問い合わせ
WHERE と HAVING 句では、 値が期待されるところではすべて副問い合わせ(副選択)が許されています。
このケースでは、 値は最初に副問い合わせを評価することで得られなくてはなりません。
副問い合わせの使い方はSQLの表現力を拡張します
Example 2-8. 副問い合わせ
もし 'Screw' という名前の部品よりも高い価格のすべての部品を知りたければ、
次のような問い合わせを行ないます。
SELECT *
FROM PART
WHERE PRICE > (SELECT PRICE FROM PART
WHERE PNAME='Screw');
結果は次のようになります。
PNO | PNAME | PRICE
-----+---------+--------
3 | Bolt | 15
4 | Cam | 25
上の問い合わせを見てみると、キーワード SELECT を2回見ることができます。
問い合わせの頭の方にある最初のひとつ - それを外部 SELECT と呼ことにします
- と WHERE 句でネストした問い合わせを始めているもの - これを内部 SELECT
と 呼ぶことにします。 外部 SELECT のすべてのタプルのために、 内部 SELECT
が評価されなくてはなりません。 すべての評価の後、'Screw' という名前のタプルの価格を知ることができ、
そして実際のタプルの価格が大きいかどうかをチェックすることができます。
もし部品を何も売っていない店を知りたければ (例えば、これらの店をデータベースから削除することができるように)、
次のように使います。
SELECT *
FROM SUPPLIER S
WHERE NOT EXISTS
(SELECT * FROM SELLS SE
WHERE SE.SNO = S.SNO);
私達の例では、すべての店が少なくとも1つは部品を売っているので、 結果は空になります。
内部 SELECT の WHERE 句の名かで、 外部 SELECT からの S.SNO を使っていることに注意してください。
上記のように、副問い合わせは外部問い合わせのすべてのタプルで評価されます。
つまり、S.SNO の値は常に外部 SELECT の実際のタプルから来ていることになります。
結合、積、例外
これらの演算子は、2つの副問い合わせから得たタプルの、 結合と積と集合の差を計算します。
Example 2-9. 結合、積、例外
次の問い合わせは 結合(UNION) のものです。
SELECT S.SNO, S.SNAME, S.CITY
FROM SUPPLIER S
WHERE S.SNAME = 'Jones'
UNION
SELECT S.SNO, S.SNAME, S.CITY
FROM SUPPLIER S
WHERE S.SNAME = 'Adams';
次のような結果になります。
SNO | SNAME | CITY
-----+-------+--------
2 | Jones | Paris
3 | Adams | Vienna
積(INTERSECT)のための例です。
SELECT S.SNO, S.SNAME, S.CITY
FROM SUPPLIER S
WHERE S.SNO > 1
INTERSECT
SELECT S.SNO, S.SNAME, S.CITY
FROM SUPPLIER S
WHERE S.SNO > 2;
結果は以下の通りになります。
SNO | SNAME | CITY
-----+-------+--------
2 | Jones | Paris
両方の問い合わせのから戻る唯一のタプルは $SNO = 2$ のものだけです。
最後に EXCEPT の例です。
SELECT S.SNO, S.SNAME, S.CITY
FROM SUPPLIER S
WHERE S.SNO > 1
EXCEPT
SELECT S.SNO, S.SNAME, S.CITY
FROM SUPPLIER S
WHERE S.SNO > 3;
結果は次の通り。
SNO | SNAME | CITY
-----+-------+--------
2 | Jones | Paris
3 | Adams | Vienna
データ定義
SQL 言語に含まれるデータ定義に使われる一式のコマンドがあります。
表の作成
データ定義のためのもっとも基本的なコマンドは 新しいリレーション(新しいテーブル)を作るものです。
CREATE TABLE table_name
(name_of_attr_1 type_of_attr_1
[, name_of_attr_2 type_of_attr_2
[, ...]]);
Example 2-10. 表の作成
店と部品データベース で定義されている表を作るには、
次のような SQL 文が使われます。
CREATE TABLE SUPPLIER
(SNO INTEGER,
SNAME VARCHAR(20),
CITY VARCHAR(20));
CREATE TABLE PART
(PNO INTEGER,
PNAME VARCHAR(20),
PRICE DECIMAL(4 , 2));
CREATE TABLE SELLS
(SNO INTEGER,
PNO INTEGER);
SQLのデータ型
以下のリストは SQL でサポートされている いくつかのデータ型です。
INTEGER: 符号つきフルワードバイナリ整数 (31 ビット精度).
SMALLINT: 符号つきハーフワードバイナリ整数 (15 ビット精度).
DECIMAL (p[,q]): p 桁の精度で、小数点以下が
q
とみなしてパックされた符号つき小数。 (15 ≧ p ≧ qq
≧ 0). もし q が省略されれば、0とみなされます。
FLOAT: 符号つきダブルワード浮動小数
CHAR(n): 長さnの 固定長文字列
VARCHAR(n): 可変長文字列で、最大長 n文字。
インデックスの作成
インデックスはリレーションへのアクセスをスピードアップするのに使います。
もしリレーションR がインデックスを属性 A に持っていたとすると、 t(A)
= a というすべてのタプルtを、 時間的に
R のサイズに比例するのではなく、 ざっとみて、時間的にそのようなタプルtの数に比例して
取り出すことができます。
SQL でインデックスを作るには、 CREATE INDEX コマンドが使われます。 文法は以下のようになります。
CREATE INDEX index_name
ON table_name ( name_of_attribute );
Example 2-11. インデックスの作成
I という名前のインデックスをリレーション SUPPLIER の属性 SNAME 上に作るには、
次のような記述を使います。
CREATE INDEX I
ON SUPPLIER (SNAME);
作成されたインデックスは、自動的に維持されます。 つまり、新しいタプルがリレーション
SUPPLIER に挿入されるといつも、 インデックス I は適合されるのです。 インデックスが存在する時にユーザが認識できる唯一の変化は
スピードの増加だけなことに注意してください。
ビュー表の作成
ビュー表は 仮想表と考えられます。 つまり、データベースの中には物理的に存在しないが、
ユーザにはそうであるかのようにうつるのです。 対照的に、基本表について論じる時、
物理的な記憶装置のどこかに、 表の各行の写しが実際に物理的に保存されています。
ビューには、物理的に分離されて区別できる保存データを持ちません。 代わりに、システムはシステムカタログのどこかに
ビュー表の定義 (つまり、ビューを実現するために、物理的に保存された基本表へ
どのようにアクセスすればよいかについてのルール)を保存します (システムカタログ
を参照してください)。 ビュー表の実装への異なるテクニックについての議論は、
SIM98
を参照してください。
SQL では CREATE VIEW コマンドがビューを定義するのに使われます。
文法は以下のようになります。
CREATE VIEW view_name
AS select_stmt
ここで、select_stmt は 選択
で定義された、 有効な選択文です。 select_stmt は ビューが作成された時には実行されないことに注意してください。
単に システムカタログに保存され、 ビューに対する問い合わせが起こった時に実行されます。
次のようなビューの定義が与えられたとしましょう (また店と部品データベースからの表です)。
CREATE VIEW London_Suppliers
AS SELECT S.SNAME, P.PNAME
FROM SUPPLIER S, PART P, SELLS SE
WHERE S.SNO = SE.SNO AND
P.PNO = SE.PNO AND
S.CITY = 'London';
ここでこの 仮想リレーション London_Suppliers を他の基本表であるかのように使うことができます。
SELECT *
FROM London_Suppliers
WHERE P.PNAME = 'Screw';
は次のような表を返します。
SNAME | PNAME
-------+-------
Smith | Screw
この結果を計算するには、データベースシステムが 基本表 SUPPLIER,SELLS,PART
への 隠れたアクセスを まずしなくてはなりません。 それら基本表に対して、ビューの定義に与えられている問い合わせを
実行することでそうします。 その後、付加的な制約 (ビューへの問い合わせで与えられます)
が結果の表を得るために用いられます。
Drop Table, Drop Index, Drop View
表(表に保存されているすべてのタプルを含む)を削除するには、 DROP TABLE コマンドが使われます。
DROP TABLE table_name;
SUPPLIER 表を削除するには、次の記述を使います。
DROP TABLE SUPPLIER;
DROP INDEX コマンドがインデックスを削除するのに使われます。
DROP INDEX index_name;
最後に DROP VIEW コマンドを使って、与えられたビューを削除します。
DROP VIEW view_name;
データの取扱
Insert Into
テーブルが作成されると( 表の作成 )、
コマンド INSERT INTOを使い、 タプルで埋めることができます。 文法は次の通りです。
INSERT INTO table_name (name_of_attr_1
[, name_of_attr_2 [,...]])
VALUES (val_attr_1
[, val_attr_2 [, ...]]);
リレーション SUPPLIER ( 店と部品データベースから
) へ最初のタプルを挿入するには、次の記述を使います。
INSERT INTO SUPPLIER (SNO, SNAME, CITY)
VALUES (1, 'Smith', 'London');
リレーション SELLS へ最初のタプルを挿入するには、次を使います。
INSERT INTO SELLS (SNO, PNO)
VALUES (1, 1);
更新
ひとつあるいは複数のリレーションのタプルの属性値を変更するには、 UPDATE
コマンドが使われます。文法は次のようになります。
UPDATE table_name
SET name_of_attr_1 = value_1
[, ... [, name_of_attr_k = value_k]]
WHERE condition;
リレーション PART で、部品 'Screw' の属性 PRICE の値を変更するには、 次のようにつかいます。
UPDATE PART
SET PRICE = 15
WHERE PNAME = 'Screw';
タプルの属性 PRICE で名前が 'Screw' の新しい値はこれで 15 となります。
削除
特定の表からタプルを削除するには、 コマンド DELETE FROM を使ってください。
文法は次のようになります。
DELETE FROM table_name
WHERE condition;
表 SUPPLIER の 'Smith' と呼ばれる店を削除するには、 次のような記述が使われます。
DELETE FROM SUPPLIER
WHERE SNAME = 'Smith';
システムカタログ
各 SQL データベースシステムには、 どの表、ビュー、インデックスなどがデータベースで定義されているかを
たどるために システムカタログ が使われています。 これらのシステムカタログは通常のリレーションのように問い合わせることができます。
例えば、ビューの定義に使われているひとつのカタログがあったとしましょう。
このカタログにはビュー定義の問い合わせが保管されています。 あるビューへの問い合わせがされると、システムはまず
カタログから ビュー定義問い合わせ を取り出し、 ユーザの問い合わせをを続ける前にビューを実現させます。
( 詳細についてはSIM98を参照してください。) システムカタログについてのさらなる情報は、
DATE
を参照してください。
埋め込み SQL
このセクションでは、SQL が ホスト言語(例えば C )の中に どのように埋め込まれることができるかの概略を記しています。
ホスト言語から SQL を使いたい2つの主な理由があります。
純粋に SQL (すなわち帰納的な問い合わせ)を使って 組み立てることのできない問い合わせがあります。
そのような問い合わせを実行するには、SQLよりも 大きな表現能力を持つホスト言語を使う必要があります。
ホスト言語で書かれたアプリケーションから簡単に データベースへアクセスを行ないたいと思います。
(例えば、グラフィカルユーザインターフェイスを持つチケット予約システムが
C で書かれており、どのチケットがまだ残っているかが データベースに保管されていて、それに埋め込み
SQLを使って アクセスすることができます。)
ホスト言語で書かれた埋め込み SQL を使っているプログラムは ホスト言語の記述と、埋め込みSQL
(ESQL) の記述から成ります。 すべての ESQL の記述は、キーワードEXEC SQL
で始まります。 プリコンパイラ (これが通常様々なSQLコマンドを実行するライブラリルーチンの
呼び出しを挿入します)によって、 ESQL 文はホスト言語の記述へ変換されます。
例 選択 を通して見てみると、 問い合わせの結果は非常に多くの場合タプルの集合であることに気づくでしょう。
多くのホスト言語は集合の操作用にデザインされていませんので、 SELECT文から返されるタプルの集合の各単一のタプルへアクセスする
メカニズムが必要となります。 このメカニズムは カーソル を宣言することで提供されます。
それから FETCH コマンドを使ってひとつのタプルを取り出し、 そのカーソルを次のタプルにセットすることができます。
埋め込み SQL の詳細な論議に関しては、 [Date and
Darwen, 1997] や [Date, 1994] や [Ullman,
1988] を参照してください。
Chapter 3. アーキテクチャ
Postgres アーキテクチャの概念
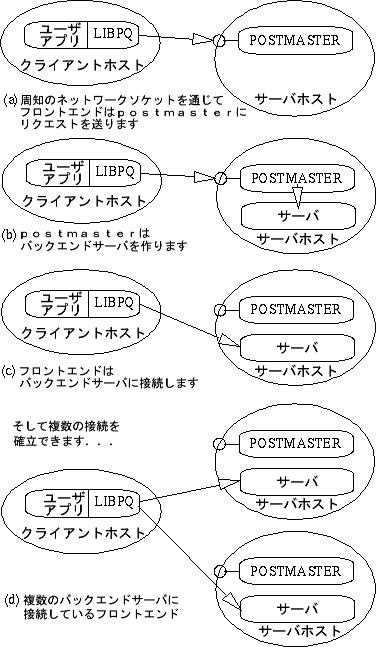
話を始める前に、まず基本的なPostgres システムアーキテクチャを理解しておいた方がよいでしょう。Postgres
の各部分が、いかにして相互に作用しているかを理解しておくと、 次の章がかなり読みやすくなるでしょう。
データベースの用語集によると、Postgresは 「ユーザごとに処理を行なう」クライアントサーバモデルを用いているということになっています。
あるPostgresセッションは、以下に示すような、 互いに協調する UNIX プロセス群(プログラム)から構成されています。
管理デーモンプロセス(postmaster)、
ユーザのフロントエンドアプリケーション(すなわち、psqlプログラム)、
1つ以上のバックエンドデータベースサーバ(postgresプロセス自身)。
単一のpostmasterは、単一のホスト上 において、与えられたデータベースの一群を管理します。そのような
データベースの一群のことをインストレーション(installation) とかサイト(site)と呼びます。1つのインストレーション内部において、
与えられたデータベースにアクセスしたいと思うフロントエンドアプリケーションは、
ライブラリを呼び出します。ライブラリは、ユーザの要求をネットワークを介して
postmaster (どのように接続が確立されるか)に送ります。
postmasterは、 次々に新しいバックエンドサーバプロセスを開始させます。
そしてフロントエンドプロセスを新しいサーバに接続します。 この時点から、フロントエンドプロセスとバックエンドサーバは
postmasterを介さずに通信を行ないます。 このため、postmasterは常に動作し続け、
要求を待ち、フロントエンドとバックエンドプロセスがいつでも 接続できるようになっているのです。
libpqライブラリを使うと、1つのフロントエンドが バックエンドプロセスに対して複数の接続を行なうことができます。
しかしながら、フロントエンドのアプリケーションは相変わらずシングルスレッドのプロセスです。
マルチスレッドのフロントエンド/バックエンド接続は libpqにおいては現在
サポートされていません。このアーキテクチャでは、フロントエンドアプリケーションは
どこで動いていてもよいにもかかわらず、 postmasterとバックエンドは、常に同一のマシン
(データベースサーバ)で動作しなければならないことを暗に示しています。 これは覚えておく必要があります。それは、クライアントマシン上でアクセスできるファイルは、
データベースサーバマシン上ではアクセスできない(または、異なったファイル名を使ってのみ
アクセスできる)かもしれないからです。
postmasterと postgres サーバは、 Postgresの "スーパーユーザ" のユーザID
で動作することにも注意してください。Postgres の スーパーユーザは、特定のユーザ(すなわち
"postgres" という名前のユーザ) である必要はありません。さらに Postgres
の スーパーユーザは、明らかに UNIX のスーパーユーザ ("root") であってはなりません。
いずれのケースにおいても、データベースに関連するすべてのファイルは、 この
Postgres スーパーユーザに属している必要があります。
Chapter 4. スタート
-
目 次
-
環境の整備
-
対話型モニタ (psql) のスタート
-
データベースの管理
新しいユーザが Postgres で作業を始める方法です。
Postgres を使うのに必要なステップのいくつかは、 Postgres のユーザの誰にでもできますが、
サイトのデータベース管理者がやらなくてはならないものもあります。 このサイト管理者はソフトウェアをインストールした人で、
データベースのディレクトリを作り、 postmaster プロセスをスタートさせた人です。
この人は UNIX のスーパーユーザ(“root”)である必要はありません。 特別なアカウントや権限なしに
Postgres をインストールして使うことができます。
もし Postgres をインストールしているなら、 インストールの説明について管理者ガイドを参照して、
インストールが完了したらこのガイドに戻ってください。
このマニュアルを通じて、 “%” 文字で始まる例は UNIX のシェルプロンプトにタイプするコマンドです。
環境の整備
このセクションでは自分の環境をフロントエンドアプリケーションを使うために
どのようにセットアップしたらよいかを論じています。 Postgres がすでに首尾よくインストールされ、
スタートしているものとしています。 Postgres のインストール方法については、
管理者ガイドとインストールノートを参照してください。
Postgres はクライアント/サーバアプリケーションです。 ユーザにとってみれば、インストールの一部のクライアント(クライアントアプリケーションの
例は対話モニタのpsqlです)にアクセスするだけです。 話を単純にするため、Postgres
がディレクトリ /usr/local/pgsql にインストールされたものとします。
ですから、ディレクトリ /usr/local/pgsql を見たら、 それを Postgres
が実際にインストールされた ディレクトリの名前と置き換えてください。 すべての
Postgres のコマンドは ディレクトリ /usr/local/pgsql にインストールされます。
ですので、このディレクトリをシェルのコマンドパスに加えてください。 もし
csh や tcsh のような バークレイ C シェル系を使っているのなら、 ホームディレクトリの
.login
ファイルに
% set path = ( /usr/local/pgsql/bin path )
を加えて下さい。 sh や ksh や bash といった Bourne shell 系を使っているなら、
ホームディレクトリの .profile ファイルに
% PATH=/usr/local/pgsql/bin:$PATH
% export PATH
を加えてください。 これからは、Postgres の bin ディレクトリが パスに加えられているものとします。
さらに、このドキュメントを通じて、“シェル変数の設定” や “環境変数の設定”
を頻繁に使います。 もし前の段落で検索パスを変更することが完全に理解できていないなら、
これから先に進む前に、使っているシェルの UNIX マニュアルページを 調べておいてください。
もしサイトの管理者がデフォルトの方法で設定をしていなかったなら、 もう少しやることが増えます。
例えば、データベースサーバマシンがリモートのマシンなら、 環境変数 PGHOST
をデータベースサーバマシンにセットする必要があります。 環境変数 PGPORT
もセットしなくてはなりません。 最後にひとつ。 もしアプリケーションプログラムをスタートしようとしていて、
postmasterに接続できないと訴えてきたら、 すぐに自分の環境が適切にセットアップされているかどうか確かめるように
サイト管理者に確かめてください。
対話型モニタ (psql) のスタート
サイトの管理者が postmaster プロセスを 適切にスタートさせて、あなたがデータベースを使えるように権限を与えていると、
あなたは(ユーザとして)アプリケーションをスタートすることができます。 前に触れたように、/usr/local/pgsql/bin
を シェルの検索パスに加えてください。 多くの場合、準備としてはこれですべてです。
Postgres バージョン 6.3 の時点で、 2つの違ったスタイルの接続がサポートされています。
サイト管理者は TCP/IP ネットワーク接続を許可するようにしているか、 もしくはデータベースへのアクセスをローカル(同じマシン)の
ソケット接続だけに制限するかしています。 データベースへの接続の問題に直面した時にこの選択は重要となります。
次のようなエラーメッセージを (psql や createdbのような) Postgres のコマンドから受け取ったとします。
% psql template1
Connection to database 'postgres' failed.
connectDB() failed: Is the postmaster running and accepting connections
at 'UNIX Socket' on port '5432'?
もしくは
% psql -h localhost template1
Connection to database 'postgres' failed.
connectDB() failed: Is the postmaster running and accepting TCP/IP
(with -i) connections at 'localhost' on port '5432'?
これは通常、(1) postmaster が走っていないか、 あるいは (2) 間違ったサーバホストに接続しようとしているかのどちらかの理由です。
次のようなエラーメッセージを受け取ったとします。
FATAL 1:Feb 17 23:19:55:process userid (2360) != database owner (268)
これはサイト管理者が postmaster を 間違ったユーザでスタートさせたことを意味します。
Postgres のスーパーユーザで再スタートしてもらうように、 管理者に伝えましょう。
データベースの管理
これでPostgres が立ち上がって走っているので、 実験するデータベースを作ることができます。
ここでデータベースを管理する基本コマンドを説明します。
多くの Postgres のアプリケーションは、 指定されなければ、 データベース名があなたのコンピュータアカウントの名前と同じであると推測します。
もしデータベース管理者があなたのアカウントをデータベースの 作成権限なしにセットアップしたなら、
あなたのデータベースの名前を伝えているでしょう。 もしこのようなケースでしたら、
データベースの作成と削除のセクションをスキップして構いません。
データベースの作成
mydb という名前のデータベースを作りたいとしましょう。 これは次にのコマンドでできます。
% createdb mydb
もしデータベースの作成に必要な権限を持っていないとすると、 次のようなメッセージを見るでしょう。
% createdb mydb
WARN:user "your username" is not allowed to create/destroy databases
createdb: database creation failed on mydb.
Postgres は与えられたサイトに いくつでもデータベースを作ることができます。
そしてあなたが作ったデータベースのデータベース管理者は自動的にあなたになります。
データベースの名前はアルファベットで始まる文字で 32文字までの長さに 制限されています。
[訳注: 日本語のファイル名がサポートされているプラットフォームでは 日本語でもかまいません。]
データベースへのアクセス
データベースを作ると、次の方法でアクセスすることができます。
対話的に SQL コマンドを入力、編集、実行できる Postgres
のターミナルモニタプログラム (例えば psql) を走らせます。
LIBPQ サブルーチンライブラリを使った C プログラムを書きます。 これで
SQL コマンドを C から送信して、 結果とステータスメッセージをプログラムに戻すことができます。
このインタフェイスは先の PostgreSQL プログラマーズガイド で説明されます。
このマニュアルの例を試すために psql をスタートさせてみたいでしょう。 mydb
データベースに対して作動させるには、 次のようなコマンドをタイプします。
% psql mydb
次のメッセージの挨拶があります。
Welcome to the POSTGRESQL interactive sql monitor:
Please read the file COPYRIGHT for copyright terms of POSTGRESQL
type \? for help on slash commands
type \q to quit
type \g or terminate with semicolon to execute query
You are currently connected to the database: template1
mydb=>
このプロンプトは、ターミナルモニタがあなたの入力を待ち、 ターミナルモニタの整備するワークスペースに
SQL の問い合わせをタイプすることができることを示します。 psql プログラムは
バックスラッシュ文字 “\” で始まるエスケープコードに応答します。 例えば、Postgres
SQLコマンドの 文法のヘルプが、次のようにタイプすることで得られます。
mydb=> \h
ワークスペースへの問い合わせの入力が終了したら、 ワークスペースの内容を
Postgres サーバに 次のようにタイプして渡すことができます。
mydb=> \g
これはサーバに問い合わせを処理しろと伝えます。 問い合わせをセミコロンで終端させると、
“\g” は必要ではありません。 psql は自動的に セミコロンで終端した問い合わせを処理します。
対話的に入力するかわりに 問い合わせをファイル(myFile としましょう)から読み込む場合には、
次のようにタイプしてください。
mydb=> \i fileName
psql から抜けて UNIX に戻るには、
mydb=> \q
とタイプすると、psql は終了してコマンドシェルに戻ります。 (他のエスケープコードについては、モニタのプロンプトで
\h
とタイプしてみてください。) 空白(すなわち、スペース、タブ、改行)は SQL
問い合わせの中で自由に使うことができます。 一行のコメントは “--” で表します。
ダッシュの後の行の最後まではすべて無視されます。 複数行のコメントと、行の中にいれるコメントは
“/* ... */” で表します。
データベースの削除
データベースmydbのデータベース管理者なら、 次の UNIX コマンドでそれを削除することができます。
% destroydb mydb
このアクションはデータベースに関連するすべてのUNIX ファイルを削除し、 とりやめることはできませんので、
これは充分な注意を払って行ってください。
Chapter 5. 問い合わせ言語
-
目 次
-
対話型モニタ
-
概念
-
新規クラスの作成
-
インスタンスのクラスへの挿入
-
クラスの問い合わせ
-
SELECT 問い合わせのリダイレクト
-
クラスの結合
-
更新
-
削除
-
集計関数の使用
Postgres の問い合わせ言語は 次世代標準の SQL3 ドラフトの異形です。 拡張できる型システム、継承、関数、ルールなどの
多くの拡張があります。 これらの特徴はもともとの Postgres の問い合わせ言語
PostQuel から引き継がれました。 このセクションでは単純な作業を行うのに
Postgres SQL をどのように使うかのあらましを提供します。 このマニュアルは
SQL の雰囲気を掴んでもらうことに重きをおいていて、 SQL の完全なチュートリアルではありません。
[MELT93] と [DATE97] を含む 多くの本が SQL について書かれています。 いくつかの言語の特徴は
ANSI 標準の一部では ないことを知っておいてください。
対話型モニタ
次の例では、前のサブセクションで説明したように mydb データベースを作っていて、
psqlをスタートさせていることとしています。 このマニュアルにある例は /usr/local/pgsql/src/tutorial/
でも見ることができます。 使い方については そのディレクトリの README
ファイルを参照してください。 チュートリアルを始めるには、次のようにします。
% cd /usr/local/pgsql/src/tutorial
% psql -s mydb
Welcome to the POSTGRESQL interactive sql monitor:
Please read the file COPYRIGHT for copyright terms of POSTGRESQL
type \? for help on slash commands
type \q to quit
type \g or terminate with semicolon to execute query
You are currently connected to the database: postgres
mydb=> \i basics.sql
\i コマンドは指定したファイルから問い合わせを読み込みます。 -s
オプションでシングルステップモードに入り、 バックエンドに問い合わせを送る前に一時停止するようになります。
この節にある問い合わせは basics.sql ファイルにあります。
psqlは、 システム情報を表示するさまざまな\dコマンドを持っています。
これらのコマンドの詳細は、 psql プロンプトで \? とタイプすることで出てくるリストを参考にしてください。
概念
Postgres の基本概念は、 オブジェクトインスタンスの名前付き集合であるクラスです。
各インスタンスにはみな、名前の付いた属性が同様にあり、 各属性は特定の型になっています。
その上、 各インスタンスには恒常的な オブジェクト識別子 (OID) があり、
インストレーションを通じて一意に決定します。 SQL の文法では表を参照するので、
表
と クラス という用語を 同じ意味で使います。 同様に、SQL の行は
インスタンスで、
SQL のカラムは 属性となります。 先に述べたように、クラスはデータベースにまとめられ、
ひとつのpostmasterプロセスに管理される データベースの集合がインストレーションあるいはサイトを構成しています。
新規クラスの作成
クラスの名前と、すべての属性の名前と型を指定することで 新しいクラスを作ることができます。
CREATE TABLE 天気 (
街 varchar(80),
最低気温 int, -- 最低気温
最高気温 int, -- 最高気温
降水量 real, -- 降水量
日付 date
);
キーワードと識別子は大文字小文字を区別しないことに注意してください。 SQL92
で許されているように、 識別子は二重引用符で囲むことによって大文字小文字を区別することが
できるようになります。 Postgres SQL は 通常のSQL の型である int, float,
real, smallint, char(N), varchar(N), date, time, timestamp といった型と同時に、
一般的に有用な型や豊富なひとそろえの幾何学的な型をサポートしています。
後でも触れますが、Postgres は 任意の数のユーザ定義のデータ型でカスタマイズすることができます。
したがって、型の名前は SQL92標準でサポートが必要とされる特別な場合を除いて、
文法的なキーワードではありません。 これまで Postgres の作成コマンドは 従来の関係システムで表を作成するのに使われるコマンド
まったく同じように見えます。 しかし、クラスには関係モデルの拡張であるプロパティを持つことが
すぐに分かります。
インスタンスのクラスへの挿入
insert 文は クラスにインスタンスを挿入するのに使います。
INSERT INTO 天気
VALUES ('サンフランシスコ', 46, 50, 0.25, '11/27/1994')
また、フラットな(ASCIIの)ファイルから 大量のデータをロードするために copy
コマンドを使うこともできます。 これは一般的に高速になります。というのも、データは単一の原子的トランザクションとして
ターゲットのテーブルに直接読み込み(あるいは書き込み)するからです。 例としては以下のようになります。
COPY INTO 天気 FROM '/home/user/weather.txt'
USING DELIMITERS '|';
ここでソースファイルへのパス名は、バックエンドサーバがファイルを直接読み込むため、
クライアントのマシンではなく、バックエンドサーバのマシンで利用可能でなくてはなりません。
クラスの問い合わせ
天気クラスは標準の関係選択と射影の問い合わせで問い合わせることができます。
これを行うには SQL の select 文を使います。 文はターゲットリスト(返される属性をリストアップしているところ)と
制約句(制限を指定しているところ)に分かれます。 例えば、天気のすべての行を入手するには次のように打ち込んでください。
SELECT * FROM 天気;
そして出力は次のようになるはずです。
+------------------+----------+----------+--------+------------+
|街 | 最低気温 | 最高気温 | 降水量 | 日付 |
+------------------+----------+----------+--------+------------+
| サンフランシスコ | 46 | 50 | 0.25 | 11-27-1994 |
+------------------+----------+----------+--------+------------+
| サンフランシスコ | 43 | 57 | 0 | 11-29-1994 |
+------------------+----------+----------+--------+------------+
| ヘイワード | 37 | 54 | | 11-29-1994 |
+------------------+----------+----------+--------+------------+
任意の式をターゲットリストに指定することもできます。 例えば次のようにできます。
SELECT 街, (最高気温+最低気温)/2 AS 平均気温, 日付 FROM 天気;
任意のブール型演算子 (andとorとnot) が問い合わせの制約句に許されています。
例えば次のようになります。
SELECT * FROM 天気
WHERE 街 = 'サンフランシスコ'
AND 降水量 > 0.0;
結果はこのようになります。
+------------------+----------+----------+--------+------------+
|街 | 最低気温 | 最高気温 | 降水量 | 日付 |
+------------------+----------+----------+--------+------------+
| サンフランシスコ | 46 | 50 | 0.25 | 11-27-1994 |
+------------------+----------+----------+--------+------------+
最後の注釈として、選択の結果を 順番に並べる、 もしくは重複したインスタンスを削除する
ように指定することができます。
SELECT DISTINCT 街
FROM 天気
ORDER BY 街;
SELECT 問い合わせのリダイレクト
選択の問い合わせは新しいクラスへリダイレクトすることができます。
SELECT * INTO TABLE temp FROM 天気;
この形式では、 select intoコマンドのターゲットリストに 指定された属性の名前と型を持つ新しいクラス
temp を作る createコマンドを暗に示しています。 それから、もちろん、その結果のクラスには
他のクラスに行うことのできる操作ならなんでもすることができるのです。
クラスの結合
これまで問い合わせは一度にひとつのクラスにアクセスするものでした。 問い合わせは一度に複数のクラスにアクセスしたり、
同じクラスの中でも同じような方法で、 一度にクラスの複数のインスタンスを処理したりすることができます。
同じもしくは違うクラスからの複数のインスタンスに同時にアクセスする 問い合わせを結合の問い合わせと呼びます。
例として、他のレコードの気温の範囲にあるすべてのレコードを 探したいとしましょう。
実際には、各 EMP インスタンスの最低気温と最高気温の属性を すべての他の
EMP インスタンスの最低気温と最高気温の属性と 比較する必要があります。
NOTE: これは概念的なモデルです。 実際の結合はもっと効率的な方法で実行されますが、
これはユーザには見えないところです。
これは次のような問い合わせで行うことができます。
SELECT W1.街, W1.最低気温 AS 最低, W1.最高気温 AS 最高,
W2.街, W2.最低気温 AS 最低, W2.最高気温 AS 最高
FROM 天気 W1, 天気 W2
WHERE W1.最低気温 < W2.最低気温
AND W1.最高気温 > W2.最高気温;
+-----------------+------+------+------------------+------+------+
|街 | 最低 | 最高 | 街 | 最低 | 最高 |
+-----------------+------+------+------------------+------+------+
|サンフランシスコ | 43 | 57 | サンフランシスコ | 46 | 50 |
+-----------------+------+------+------------------+------+------+
|サンフランシスコ | 37 | 54 | サンフランシスコ | 46 | 50 |
+-----------------+------+------+------------------+------+------+
NOTE: このような結合の意味は、 制約句が問い合わせで示したクラスの直積に定義された式が
真であるということです。 制約句が真である直積のインスタンスのために、 Postgres
は ターゲットリストに指定された値を計算して返します。 Postgres SQLは そのような式の重複した値に何の意味も与えません。
これはPostgresが時に 同じターゲットリストを幾度か再計算することを意味します。
これはブール型の式が "or" でつながったときに度々起こります。 そのような重複を削除するには、
select
distinct 文を使わなくてはなりません。
このケースで、W1 と W2 は両方とも天気クラスのインスタンスの代用で、 両方の範囲ともにクラスのすべてのインスタンスをまたいでいます。
(多くのデータベースシステム用語として、 W1 と W2 は 範囲変数として知られています。)
問い合わせには任意の数のクラス名と代用を含めることができます。
更新
既存のインスタンスを update コマンドを使って更新することができます。 11月28日からの気温の表示がすべて2度高かったことに気づいたなら、
次のようにしてデータを更新できます。
UPDATE 天気
SET 最高気温 = 最高気温 - 2, 最低気温 = 最低気温 - 2
WHERE date > '11/28/1994';
削除
delete コマンドを使って削除を実行できます:
DELETE FROM 天気 WHERE 街 = 'ヘイワード';
ヘイワードのすべての天気レコードが削除されます。 次のような形式の問い合わせには注意してください。
DELETE FROM クラス名;
制約句がないと、delete は 与えられたクラスのすべてのインスタンスを単に削除して空にします。
これを行う前にシステムは確認を取りません。
集計関数の使用
他の多くの問い合わせ言語のように、 PostgreSQLは 集計関数をサポートします。
Postgres の集計関数の現在の実装には いくつかの制約があります。 特に、インスタンスの集合への
count,
sum,
avg
(平均), max (最高), min (最小) などの計算をする集計関数がありますが、
集計関数は問い合わせのターゲットリストにのみ使うことができますが、 制約句(where句)に直接使うことはできません。
例として、
SELECT max(最低気温) FROM 天気;
は許されますが、
SELECT 街 FROM 天気 WHERE 最低気温 = max(最低気温);
はダメです。 しかし、多くの場合問い合わせを言い換えることで 望む結果を得ることができます。
ここでは副問い合わせを使います:
SELECT 街 FROM 天気 WHERE 最低気温 = (SELECT max(最低気温) FROM 天気);
集計関数はまたgroup by句を持つことができます:
SELECT 街, max(最低気温)
FROM 天気
GROUP BY 街;
Chapter 6. 高度な Postgres SQL の特徴
-
目 次
-
継承
-
非原子的な値
-
タイムトラベル
-
さらに高度な特徴
これまでは Postgres SQL を使ってあなたのデータにアクセスするための基礎的な部分についてカバーしてきましたが、今後は従来のデータ管理ソフトとは一線を画すような
Postgres の特徴についてご紹介してゆきましょう。これらの特徴には、継承、タイムトラベル、及び非原子的データ値(配列や設定値を持つ属性)があげられます。この章に記述されている例題は、チュートリアルディレクトリの
advance.sql
の中にも見ることができます。 (使用法は、前章 Chapter 5
を参照してください。)
継承
2つのクラスを作成してみましょう。 capitals クラスは、州都である cites を含みます。予想どおり、capitals
クラスは、cities クラスから継承されます。
CREATE TABLE cities (
name text,
population float,
altitude int -- (in ft)
);
CREATE TABLE capitals (
state char2
) INHERITS (cities);
この場合、capitals のインスタンスは、親である cites インスタンスから全ての属性
( cities、population、及び、altitude )を継承します。name のデータ型は text
です。これは可変長 ASCII 文字列を表すPostgresネイティブのデータ型です。population
のデータ型は floatで、倍精度浮動少数点のための Postgresネイティブのデータ型です。
State capitals は、さらにそれらの州を示す state という属性を持っています。Postgres
は、ゼロ個以上のクラスを継承することが出来、そして問い合わせもクラスの中のすべてのインスタンス、またはクラスの中のすべてのインスタンスとその継承先も参照することが出来ます。
NOTE: 継承の階層構造は、方向性の有るらせん状グラフです。
例えば、次の問い合わせは、標高が 500ft より高い全ての都市を探し出します:
SELECT name, altitude
FROM cities
WHERE altitude > 500;
+----------+----------+
|name | altitude |
+----------+----------+
|Las Vegas | 2174 |
+----------+----------+
|Mariposa | 1953 |
+----------+----------+
一方、州都を含む全ての都市で 500ft より高い標高に位置しているの都市をを探すための問い合わせは、以下の様になります:
SELECT c.name, c.altitude
FROM cities* c
WHERE c.altitude > 500;
これは、以下の結果を返します:
+----------+----------+
|name | altitude |
+----------+----------+
|Las Vegas | 2174 |
+----------+----------+
|Mariposa | 1953 |
+----------+----------+
|Madison | 845 |
+----------+----------+
ここで、cities の後の “*”(アスタリスク)は、その問い合わせがすべての
cities、およびその継承構造における cities 配下のすべてのクラスに対して実行されることを示しています。
既に紹介した数々のコマンド ( select や update、そして delete
)は、その他のコマンド、例えば alter の様に、この“*”表記法をサポートします。
非原子的な値
リレーショナルモデルの定義の1つが、リレーションの属性は原子的であるということです。しかし、Postgres
は、この制限を持っていません; 属性は、それら自身が問い合わせ言語からアクセスされることが可能な部分値を含むことができます。
例えば、あなたはベース型が配列である属性を作ることができます。
配列
Postgres はインスタンスの属性に固定長あるいは可変長の多次元配列を定義することを許してます。配列は、どんなベース型あるいはユーザーによって定義されたデータ型からでも作られることができます。それらの使用法を説明するために、まずベース型の配列クラスをってみます。
CREATE TABLE SAL_EMP (
name text,
pay_by_quarter int4[],
schedule text[][]
);
上記のクエリーは SAL_EMP というクラスに、text 型の name、従業員の4半期までにその従業員の給料を表す
int4
型一次元配列の pay_by_quarter、従業員の1週間のスケジュールを表す
text
型二次元配列の schedule を作成します。 幾つか挿入 (INSERT) をしてみます;
配列に添字をする場合、値を"[]"(ブラケット)に入れ、そしてコンマによってそれらを切り離すことに注意してください。もしあなたがC言語を知っているなら、これは構造体を初期化する構文と同じです。
INSERT INTO SAL_EMP
VALUES ('Bill',
'{10000, 10000, 10000, 10000}',
'{{"meeting", "lunch"}, {}}');
INSERT INTO SAL_EMP
VALUES ('Carol',
'{20000, 25000, 25000, 25000}',
'{{"talk", "consult"}, {"meeting"}}');
デフォルトでは、 Postgres は配列のために「1始まり」の番号付けを使います
− すなわち、n個の要素が有る配列は、配列[1]から始まり配列[n]で終わります。
さあ、幾つかの問い合わせを SAL_EMP に対して行うことができるようになりました。
まず、一度に配列のひとつの要素にアクセスする方法をお見せしましょう。 以下の問い合わせは、給料が第2四半期に変化したその従業員の名前を検索します:
SELECT name
FROM SAL_EMP
WHERE SAL_EMP.pay_by_quarter[1] <>
SAL_EMP.pay_by_quarter[2];
+------+
|name |
+------+
|Carol |
+------+
以下の問い合わせは、すべての従業員の第3四半期の給料を検索します:
SELECT SAL_EMP.pay_by_quarter[3] FROM SAL_EMP;
+---------------+
|pay_by_quarter |
+---------------+
|10000 |
+---------------+
|25000 |
+---------------+
さらに、配列あるいは部分配列の任意のスライスにアクセスすることができます。
以下の問い合わせは、Billさんの今週始め2日間のスケジュールの一番最初の項目だけを検索します。
SELECT SAL_EMP.schedule[1:2][1:1]
FROM SAL_EMP
WHERE SAL_EMP.name = 'Bill';
+-------------------+
|schedule |
+-------------------+
|{{"meeting"},{""}} |
+-------------------+
タイムトラベル
Postgres v6.2 から、タイムトラベルはサポートされなくなりました。
これには以下に示す様にいくつかの理由があります: 性能への影響、記憶サイズ、及び、
短時間にpg_time のファイルサイズが無限大に増大してしまう、等。
トリガーのような新しい機能を使うことにより、タイムトラベルが必要とされない場合(多くのユーザにとっては、このような場合がほとんどなのですが)に特にオーバーヘッドをかけることもなく、必要な場合にだけタイムトラベルの様な動作を行わせることができるようになります。
さらに情報が必要なときは、contrib ディレクトリにあるサンプルを見てください。
タイムトラベルは見捨てられています:: この章にあるタイムトラベルの残りの文章は、同じ目的を達成する新しい構文で書きなおされるまで、ずっとこのままです。何処かにボランティアはいませんか?
- thomas 1998-01-12
Postgres は、タイムトラベルの概念をサポートします。この機能により、ユーザは時系列に沿った問合せを行うことができるようになります。例えば、現在のマリポサ市の人口を探す問い合わせは以下のようになります:
SELECT * FROM cities WHERE name = 'Mariposa';
+---------+------------+----------+
|name | population | altitude |
+---------+------------+----------+
|Mariposa | 1320 | 1953 |
+---------+------------+----------+
Postgres は、現時点において正しいバージョンのマリポサ市のレコードを自動的に発見してくれます。また、この問い合わせに時刻(あるいは時間)の範囲を与えることが出来ます。例えば、マリポサ市の過去と現在の人口を見るために、以下の様な問い合わせをするとします:
SELECT name, population
FROM cities['epoch', 'now']
WHERE name = 'Mariposa';
"epoch" は、システムクロックの最初を示しています。
NOTE: UNIXシステムでは、この値は常に1/1/1970
の 0:00:00 GMTです。
もしあなたが今までのすべての例題を実行してきたならば、上記の問い合わせは以下の結果を返します:
+---------+------------+
|name | population |
+---------+------------+
|Mariposa | 1200 |
+---------+------------+
|Mariposa | 1320 |
+---------+------------+
デフォルトでのタイムレンジの始まりはシステムが一番最初として表現する時間で、そしてデフォルトのタイムレンジの終了は現在の時間です、したがって上記のタイムレンジは
[,] の様に省略することが出来ます。
さらに高度な特徴
Postgres は、この SQL 初心者向けチュートリアルマニュアルで触れられている事以外にも多くの特徴を兼ね備えています。
それらについては、ユーザーズガイトとプログラマーズガイドで詳細に紹介されています。
文献
Selected references and readings for SQL and Postgres.
SQL Reference Books
Reference texts for SQL features.
The Practical SQL Handbook , Judity Bowman, Sandra Emerson, and
Marcy Damovsky, ISBN: 0-201-44787-8, Addison-Wesley, 1997.
A Guide to the SQL Standard , C. J. Date and Hugh Darwen, ISBN:
0-201-96426-0, Addison-Wesley, 1997.
An Introduction to Database Systems , C. J. Date, Addison-Wesley,
1994.
Understanding the New SQL , Jim Melton and Alan R. Simon, ISBN:
1-55860-245-3, Morgan Kaufmann, 1993.
Principles of Database and Knowledge , Jeffrey D. Ullman, Computer
Science Press .
PostgreSQL-Specific Documentation
This section is for related documentation.
The PostgreSQL Administrator's Guide , The PostgreSQL Global
Development Group.
The PostgreSQL Developer's Guide , The PostgreSQL Global Development
Group.
The PostgreSQL Programmer's Guide , The PostgreSQL Global Development
Group.
The PostgreSQL Tutorial Introduction , The PostgreSQL Global
Development Group.
The PostgreSQL User's Guide , The PostgreSQL Global Development
Group.
Enhancement of the ANSI SQL Implementation of PostgreSQL , Stefan
Simkovics, Department of Information Systems, Vienna University of Technology
.
The Postgres95 User Manual , A. Yu and J. Chen, The POSTGRES
Group , University of California, Berkeley CA.
Proceedings and Articles
This section is for articles and newsletters.
Partial indexing in POSTGRES: research project , Nels Olson,
ISSN: UCB Engin T7.49.1993 O676, University of California, Berkeley CA.
A Unified Framework for Version Modeling Using Production Rules in
a Database System , L. Ong and J. Goh, ISSN: ERL Technical Memorandum
M90/33, University of California, Berkeley CA.
The Postgres Data Model , L. Rowe and M. Stonebraker.
Generalized
partial indexes , P. Seshadri and A. Swami, ISSN: Cat. No.95CH35724,
IEEE Computer Society Press.
The Design of Postgres , M. Stonebraker and L. Rowe.
The Design of the Postgres Rules System, M. Stonebraker, E. Hanson,
and C. H. Hong.
The Postgres Storage System , M. Stonebraker.
A Commentary on the Postgres Rules System , M. Stonebraker, M.
Hearst, and S. Potamianos.
The
case for partial indexes (DBMS) , M. Stonebraker.
The Implementation of Postgres , M. Stonebraker, L. A. Rowe,
and M. Hirohama.
On Rules, Procedures, Caching and Views in Database Systems ,
M. Stonebraker and et al.